Anthropic, one of OpenAI’s top competitors, introduced its latest Large Language Model (LLM), called Claude 3, in early March. The AI community was taken by surprise as Claude 3’s capabilities proved to be superior to that of OpenAI’s flagship GPT-4, marking the first instance of GPT-4 being outperformed. Meanwhile, Google’s Gemini Ultra trailed behind both.
The launch of Claude 3 ushered in what appears to be the second phase of LLM competition, where companies prioritize in-context understanding, robustness and reasoning over mere scale. The generative AI sector has recently been accelerating rapidly on the back of contributions from key players including OpenAI, Anthropic, Google, Meta and Mistral AI.
The first phase of the LLM competition was set in motion following the debut of OpenAI’s ChatGPT in late 2022. This phase was characterized by a race to scale, with companies vying to develop increasingly powerful models primarily focused on size and computational capabilities.
OpenAI’s GPT-4 once epitomized the zenith of these efforts, setting benchmarks for what generative AI could achieve in terms of understanding and generating human-like text. Many subsequent LLMs, including Google’s Gemini series, Anthropic’s Claude 2, Meta’s Llama series and Mistral AI’s Mistral Large, continued to challenge the dominance of GPT-4, yet failed.
However, the ascendancy of Anthropic’s Claude 3 signifies a paradigm shift to a new era. Now the battlefield has become multi-polarized.
Phase Two Begins
We think GPT-4 being surpassed by Claude 3 marks the second stage of LLM contests:
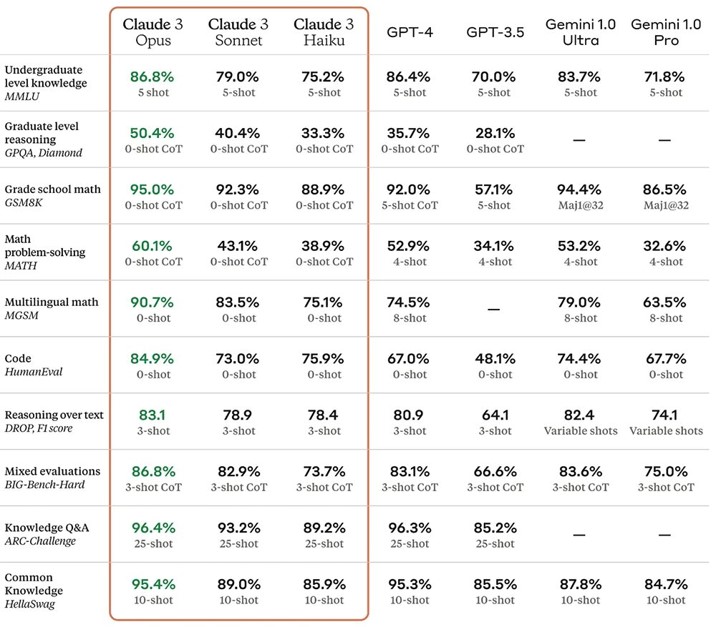
- The Claude 3 family showcases three cutting-edge models, named Claude 3 Haiku, Claude 3 Sonnet, and Claude 3 Opus, arranged by their growing capabilities. Claude 3 Opus is superior to GPT-4 in all key performance benchmarks.
- Claude 3 has an unprecedented level of understanding in advanced science. For example, Kevin Fischer, a theoretical quantum physicist, was astounded by Claude 3’s grasp of his doctoral thesis.
- Claude 3 not only comprehends complex scientific principles but also exhibits a degree of emergent capability. For example, another expert in quantum computing was taken aback when Claude 3 reinvented his algorithm with just two prompts, without seeing his yet-to-be-published paper.
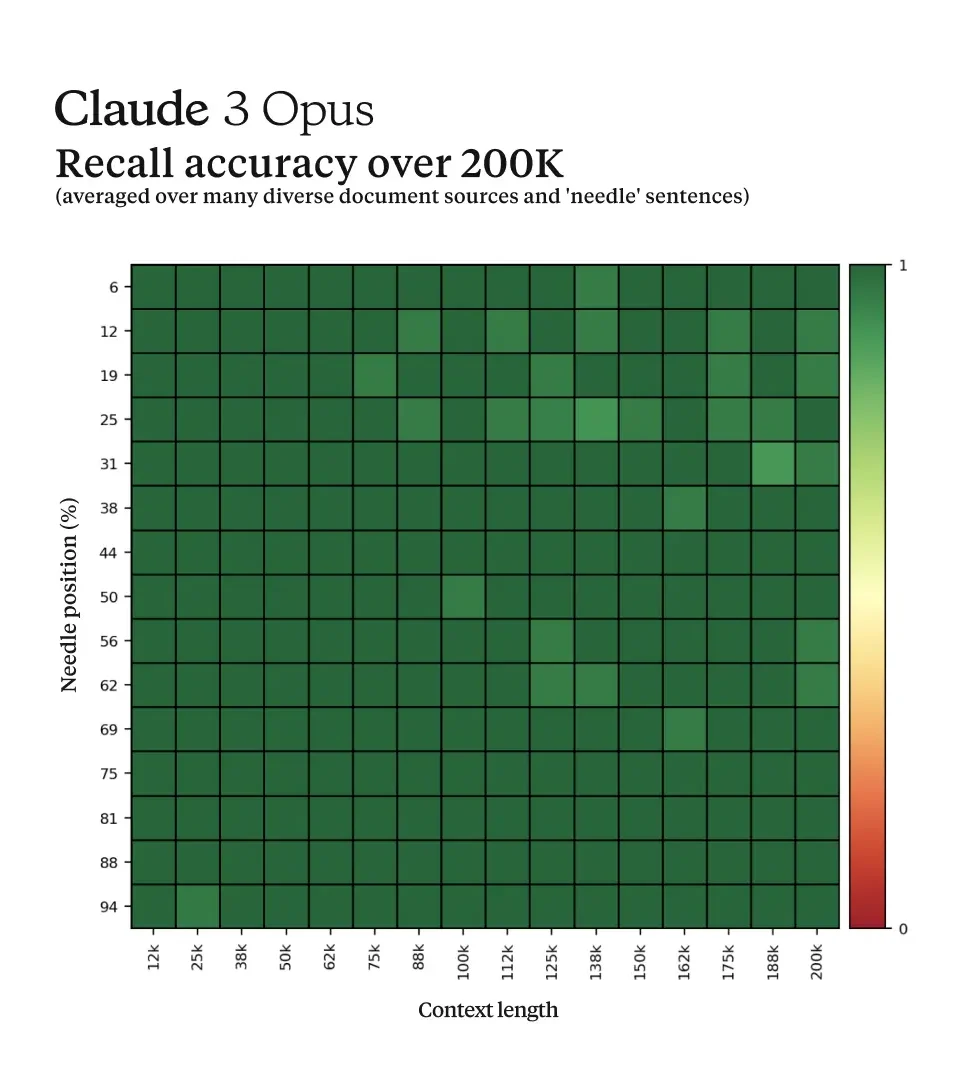
- The degree of Claude 3’s “meta-awareness” (can be just superb pattern-matching alignments with data created by humans) lets it figure out that it is being tested in a simulation in the needle-in-the-haystack evaluation. This testing method, just like “finding a needle in a haystack,” is designed to ascertain whether LLMs can accurately pinpoint key facts within hundreds of thousands of words. Initially invented by Greg Kamradt, a member of the open-source community, this approach quickly gained traction among major AI companies. Giants like Google, Mistral AI, and Anthropic now commonly showcase their new models’ performance through these tests.

What does it mean to be in the Stage Two of LLM competition?
Linear vs Accelerated Progress
We have observed that currently there is an accelerated rate of innovation progress in the LLM battlefield. Even though it is only March, a host of contenders, such as Google’s Gemini Ultra and Mistral AI’s Mistral Large, have already attempted to take the throne from OpenAI’s GPT-4. However, it was Anthropic’s Claude 3 Opus that emerged on top, marking a pivotal breakthrough in the ongoing quest for supremacy.
Open vs Close
The rivalry within the realm of closed-source LLMs has escalated, positioning closed-source generative AI technologies as a pivotal tactic for forging any company’s defensive “moat”.
For instance, Mistral AI initially captured attention with its impressive open-source Mixture of Experts (MoE) lean models but has now pivoted to spotlight its proprietary Mistral Large model.
Advice for Developers
In the ever-changing LLM landscape, developers need to understand that given your specific use case, making assessments that truly gauge a model’s strengths and weaknesses becomes more important than blindly trusting the general benchmarks:
- Stay agile, ready to integrate newer models or versions as they become available. Today’s choice might need reassessment tomorrow.
- A blend of understanding each model’s unique strengths, continuous exploration and adaptation cannot be more emphasized, given the specific needs of your applications.
- Much like the varied tactics of donning armor for battle, adapting your prompts is crucial to maximizing a model’s potential. Comprehensive tutorials are readily available online to guide you.